大數據開發之Kafka 存儲選型、數據處理與存儲支持服務
在當今數據驅動的時代,Apache Kafka憑借其高吞吐、低延遲、可擴展和高可靠的特性,已成為大數據生態系統中不可或缺的基石。它不僅是實時數據管道的核心,更是流式數據處理的樞紐。本文將深入探討Kafka在存儲選型、數據處理模式以及存儲支持服務方面的關鍵考量與實踐。
一、Kafka的存儲選型:日志結構的核心設計
Kafka的存儲設計是其高性能的基石。其核心是一個持久化的、分布式的、分區的、可復制的提交日志(Commit Log)。
- 基于日志的存儲模型:Kafka將所有消息順序追加到日志文件中。這種“僅追加”(Append-Only)的設計,結合順序磁盤I/O,即使在普通硬件上也能實現極高的讀寫吞吐量,遠超隨機讀寫。
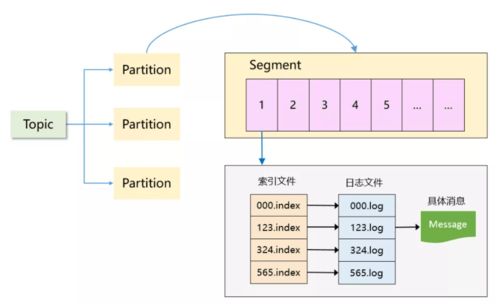
- 分區(Partition)與分段(Segment):
- 分區:每個主題(Topic)被劃分為一個或多個分區,實現了數據的并行處理和水平擴展。分區是Kafka并行度的基本單位。
- 分段:每個分區在物理上由一系列順序的、大小相等的日志分段文件(Segment)組成。當前活躍的寫入文件稱為活躍分段。Kafka會定期關閉舊的活躍分段并創建新的,這個過程稱為日志滾動。
- 存儲策略與數據保留:
- 基于時間的保留:配置
log.retention.hours等參數,刪除早于指定時間的消息。
- 基于大小的保留:配置
log.retention.bytes,當分區總日志大小超過閾值時,刪除最舊的分段。
- 壓縮主題(Compacted Topic):對于鍵值對數據,Kafka提供了日志壓縮功能。它只為每個鍵保留最新的值,從而在保證關鍵狀態不丟失的前提下,有效節省存儲空間,常用于存儲數據表的變更日志(CDC)或應用程序狀態。
- 存儲選型考量:
- 磁盤類型:推薦使用高性能的機械硬盤(HDD)或固態硬盤(SSD)。Kafka的順序讀寫特性使得高性能HDD通常已能滿足需求,而對延遲極度敏感的場景可考慮SSD。
- 文件系統:EXT4或XFS是經過驗證的穩定選擇。XFS在處理大量文件時通常表現更佳。
- RAID配置:通常不建議使用RAID,Kafka自身的副本機制(Replication)已提供了數據可靠性。直接使用JBOD(Just a Bunch Of Disks)配置,讓每個磁盤獨立存儲部分分區數據,能最大化I/O吞吐量和磁盤利用率。
二、Kafka的數據處理:從消息隊列到流處理平臺
Kafka早已超越其最初作為消息隊列的定位,演變為一個完整的流式數據處理平臺。
- 核心數據流模式:
- 生產與消費:生產者(Producer)將數據發布到指定主題,消費者(Consumer)以消費者組(Consumer Group)的形式訂閱并拉取數據,實現解耦的、可擴展的數據傳輸。
- 精確一次語義(Exactly-Once Semantics, EOS):通過冪等生產者和事務API,Kafka能夠確保在生產者到Kafka,以及Kafka到消費者的數據處理流程中,消息既不丟失也不重復,這對于金融、計費等關鍵業務至關重要。
- Kafka Connect:數據集成框架:
- 作為Kafka生態的一部分,Kafka Connect專注于與外部存儲系統(如數據庫、數據倉庫、搜索引擎、文件系統)之間可擴展、可靠的數據導入(Source Connector)和導出(Sink Connector)。它簡化了構建和管理數據管道的工作,用戶無需編寫代碼即可實現與數百種數據源的連接。
- Kafka Streams:流處理庫:
- 這是一個用于構建實時流處理應用程序的客戶端庫。它將流處理邏輯直接嵌入到Java/Scala應用程序中,無需額外的流處理集群。它提供了豐富的DSL(領域特定語言),支持窗口、連接、聚合、狀態存儲等復雜操作,并與Kafka的狀態管理和容錯機制深度集成。
- ksqlDB:事件流數據庫:
- 建立在Kafka Streams之上的聲明式SQL引擎。它允許開發者使用熟悉的SQL語句對Kafka中的流數據進行查詢、轉換和物化,極大地降低了流式應用程序的開發門檻,適用于實時監控、異常檢測和動態儀表板等場景。
三、存儲支持服務:保障數據可靠性與可用性
Kafka的強大離不開其背后一系列存儲支持服務的保障。
- 副本機制(Replication):
- 每個分區的數據會被復制到多個Broker上(通過
replication.factor配置)。其中一個副本被選舉為領導者(Leader),負責處理所有讀寫請求;其他副本作為追隨者(Follower),從領導者異步同步數據。這確保了即使個別Broker宕機,數據依然可用且不丟失。
- 控制器(Controller):
- 集群中某個Broker會被選舉為控制器,負責管理分區副本的領導者選舉、分區重分配以及集群元數據變更等關鍵任務,是保障集群一致性和協調性的“大腦”。
- ZooKeeper/KRaft的協調服務:
- 傳統模式:Kafka重度依賴Apache ZooKeeper來存儲集群元數據(如Broker、主題、分區信息)和進行領導者選舉。
- KRaft模式:這是Kafka未來的發展方向。Kafka正在移除對ZooKeeper的依賴,使用其自身實現的KRaft共識協議來管理元數據。KRaft模式簡化了部署架構,提高了可擴展性和運維效率,是生產環境部署的推薦選擇。
- 監控與運維:
- JMX指標:Kafka暴露了豐富的JMX指標,涵蓋Broker、生產者、消費者、主題、分區等各個維度,是監控集群健康、吞吐量、延遲和積壓情況的基礎。
- 日志與審計:Broker日志、控制器日志、狀態變更日志等是故障排查和審計追蹤的重要依據。
- 工具集:Kafka提供了
kafka-topics,kafka-consumer-groups,kafka-configs等命令行工具,以及第三方運維平臺(如CMAK/Kafka Manager, Confluent Control Center),極大地方便了集群的日常管理。
理解Kafka的存儲設計、數據處理能力及其支持服務體系,是構建高效、穩定、可擴展的大數據實時架構的關鍵。從作為可靠數據總線的存儲基石,到通過Connect、Streams和ksqlDB實現強大的流式處理,再到由副本、控制器和共識協議構成的堅實后盾,Kafka為現代數據密集型應用提供了從數據攝入、處理到分發的完整解決方案。開發者應根據具體業務場景(如數據吞吐量、延遲要求、語義保證、運維復雜度),做出合理的存儲選型與架構設計,從而充分發揮Kafka的技術潛力。
如若轉載,請注明出處:http://m.wudima.cc/product/19.html
更新時間:2026-05-15 15:29:24